
티스토리 뷰
목차
1. 랜덤 I/O와 순차 I/O 디스크 읽기
2. 인덱스
1. 랜덤 I/O와 순차 I/O 디스크 읽기
랜덤 I/O는 하드 디스크 드라이브의 플래터를 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미한다.
3개의 페이지를 디스크에 기록하기 위해 순차 I/O는 1번의 시스템 콜로 디스크의 헤더를 1번 움직이고,
랜덤 I/O는 3번의 시스템 콜로 디스크 헤드를 3번 움직인다. 디스크의 성능은 디스크 헤더의 위치 이동없이 얼마나 많은 데이터를 한 번에 기록하느냐에 의해 결정되기 때문에 랜덤 I/O 작업이 부하가 훨씬 크다.
테이블의 레코드 대부분을 읽는 작업에서는 인덱스 레인지 스캔(랜덤 I/O)이 아닌 풀 테이블 스캔(순차 I/O)을 사용하도록 유도할 수 있지만 그 외에는 랜덤 I/O를 순차 I/O로 바꿔서 실행할 방법은 많지 않다.
결국 쿼리를 튜닝하는 것은 랜덤 I/O 자체를 줄이는 것으로 쿼리를 처리하는 데 꼭 필요한 데이터만 읽도록 쿼리를 개선하는 것을 의미한다.
2. 인덱스
컬럼의 값과 레코드가 저장된 주소를 키와 값의 쌍으로 삼아 컬럼의 값을 정렬해서 보관하는 데이터베이스 객체이다.
데이터베이스 테이블의 모든 데이터를 검색해서 원하는 결과를 가져오려면 시간이 오래 걸리기 때문에 인덱스를 만들어 두고 활용한다. 인덱스는 데이터가 저장될 때마다 항상 값을 정렬해야 하므로 저장하는 과정이 복잡하고 느리지만 이미 정렬돼 있어서 아주 빨리 원하는 값을 찾아올 수 있다.
결론적으로 인덱스는 데이터 저장 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다.
따라서 테이블의 인덱스를 추가할지 말지는 데이터의 저장 속도를 어디까지 희생할 수 있는지, 읽기 속도를 얼마나 더 빠르게 만들어야 하느냐에 따라 결정된다.
(1) B-Tree 인덱스
데이터베이스 인덱싱 알고리즘 가운데 가장 많이 사용되는 B-Tree(Balanced Tree) 인덱스는 컬럼의 원래 값을 변형시키지 않고 인덱스 구조체 내에서 항상 정렬된 상태를 유지한다.
● 인덱스 구조

B-Tree 의 구조는 루트 노드, 브랜치 노드, 리프 노드로 이루어져 있고 가장 하위의 리프 노드는 항상 실제 데이터 레코드를 찾아가기 위한 주솟값을 가지고 있다. (MyISAM 테이블은 세컨더리 인덱스가 물리적인 주소를 가지는 반면 InnoDB 테이블은 프라이머리 키를 주소처럼 사용한다.)
대부분의 RDBMS의 데이터 파일에서 레코드는 특정 기준으로 정렬되지 않고 임의의 순서로 저장된다. 하지만 InnoDB 테이블에서 레코드는 클러스터되어 디스크에 저장되므로 기본적으로 프라이머리 키 순서로 정렬되어 저장된다.
B-Tree 인덱스와 클러스터링 인덱스

InnoDB 테이블에서 인덱스를 통해 레코드를 읽을 때는 인덱스에 저장돼 있는 프라이머리 키 값을 이용해 프라이머리 키 인덱스를 한번 더 검색한 후, 프라이머리 키 인덱스의 리프 페이지에 저장돼 있는 레코드를 읽는다. 즉, InnoDB 스토리지 엔진에서는 모든 세컨더리 인덱스 검색에서 데이터 레코드를 읽기 위해서는 반드시 클러스터링 인덱스를 한번 더 검색해야 한다.
● 인덱스 키 추가
레코드를 추가하면 B-Tree에 인덱스 키 추가 작업이 발생한다. 이 때 저장될 키 값을 이용해 B-Tree 상의 적절한 위치를 검색해야 한다. 저장될 위치가 결정되면 레코드의 키 값과 대상 레코드의 주소 정보를 B-Tree의 리프 노드에 저장한다. 리프 노드가 꽉 차서 더는 저장할 수 없을 때는 리프 노드가 분리돼야 하는데, 이는 상위 브랜치 노드까지 처리의 범위가 넓어진다. 이러한 작업 탓에 B-Tree는 상대적으로 쓰기 작업에 비용이 많이 든다.
(체인지 버퍼)
InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만 디스크로부터 읽어와서 업데이트 해야 한다면 이를 즉시 실행하지 않고 임시 공간에 저장해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상시킨다. 이때 사용하는 임시 메모리 공간을 체인지 버퍼라고 한다.
* 체인지 버퍼에 임시로 저장된 인덱스 레코드 조각은 이후 백그라운드 스레드(머지 스레드)에 의해 병합된다.
* 유니크 인덱스는 반드시 중복 여부를 체크해야 하기 때문에 체인지 버퍼를 사용할 수 없다.
● 인덱스 키 삭제
레코드 삭제로 B-Tree 인덱스 키 값이 삭제될때는 해당 키 값이 저장된 리프 노드를 찾아 삭제 마크하는 작업만 발생한다. 이렇게 삭제 마킹된 인덱스 키 공간은 계속 그대로 방치되거나 재활용할 수 있다. 이 작업 역시 디스크 I/O가 필요한 작업이다.
● 인덱스 키 변경
인덱스 키 값은 그 값에 따라 저장될 리프 노드의 위치가 결정되므로 B-Tree의 키 값이 변경되는 경우 기존 인덱스 키 값을 삭제한 후 새로운 인덱스 키 값을 추가하는 작업으로 처리되고, InnoDB 테이블은 이 작업 모두 체인지 버퍼를 활용해 지연 처리될 수 있다.
● 인덱스 키 검색
B-Tree 인덱스를 이용한 검색은 100% 일치, 값의 앞부분만 일치하는 경우, 부등호(<, >) 비교 조건에서 인덱스를 사용할 수 있다.
다음은 인덱스 키 검색을 사용할 수 없는 경우이다.
- 인덱스를 구성하는 키 값의 뒷부분만 검색하는 용도
SELECT * FROM CUSTOMER WHERE NAME LIKE '%A';
- 함수나 연산을 수행한 결과로 정렬하거나 검색하는 작업
(인덱스의 키 값에 변형이 가해진 후 비교되는 경우 변형된 값은 B-Tree 인덱스에 존재하는 값이 아니다.)
SELECT * FROM EMP WHERE TO_CHAR(hire_date, 'YYYY') = '2021';
● 인덱스 시간 복잡도
MySQL 인덱스는 B-Tree 계열(B+Tree, B*Tree) 자료구조를 사용한다.
B-Tree는 이진 탐색 트리(binary search tree, BST)의 일반화된 형태이다. 이진 탐색 트리가 자식 노드가 2개 이하인 트리라면, B-Tree는 자식 노드가 2개 이상인 트리이다. 즉, 노드의 개수를 늘리고 트리의 전체 높이를 줄여서 빠른 탐색 속도를 얻을 수 있다. 최대 M개의 자식을 가질 수 있는 B-Tree를 M차 B-Tree라고 한다.
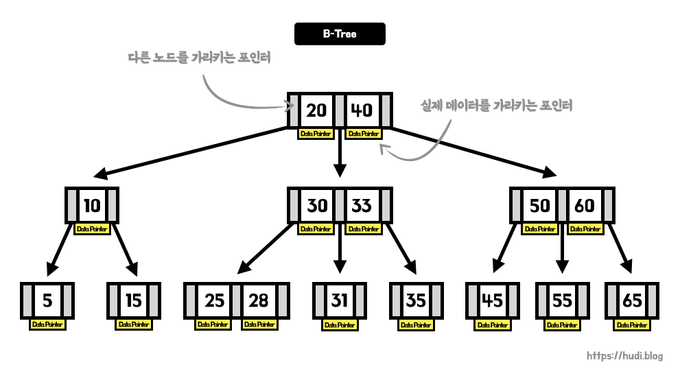
B-Tree는 정렬된 트리이므로 탐색이 의 시간 복잡도를 갖는다. 28이라는 숫자를 찾는데 고작 4번의 탐색을 거친다.
B+Tree
일반적으로 DBMS에서는 B+Tree를 사용하는데 B+Tree는 리프 노드가 연결리스트 형태를 가진다.
부등호 연산에서 B-Tree는 트리 순회를 하지만 B+Tree는 리프 노드를 순차 검색할 수 있어 B-Tree에 비해 빠르다.
(2) 클러스터링 인덱스
MySQL에서 InnoDB 엔진만 지원하는 기능으로 프라이머리 키 값이 비슷한 레코드끼리 묶어서 저장하는 것을 의미한다.
프라이머리 키 값이 변경된다면 그 레코드의 물리적인 저장 위치가 바뀌기 때문에 테이블은 프라이머리 키 값 자체에 대한 의존도가 상당히 크다. 테이블 자체가 클러스터링 되기 때문에 "클러스터링 테이블"과 동의어로 사용한다.
클러스터링 인덱스를 사용해 조금 느린 쓰기를 감수하고 읽기를 빠르게 유지할 수 있다.

(테이블에 프라이머리 키가 없는 경우)
InnoDB 엔진이 다음 우선순위대로 대체할 컬럼을 클러스터링 키로 선택한다.
- 프라이머리 키가 있으면 기본적으로 프라이머리 키를 선택
- NOT NULL 옵션의 유니크 인덱스 중에서 첫 번째 인덱스를 선택
- 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후 선택
InnoDB 테이블의 모든 세컨더리 인덱스는 해당 레코드의 주소가 아니라 프라이머리 키 값을 저장한다.

따라서 클러스터링 키 값이 변경되면 레코드의 주소가 변경되는데 이때, 모든 세컨더리 인덱스가 업데이트 되는 오버헤드가 발생하지 않는다.
● 클러스터링 인덱스 키의 크기
클러스터링 테이블의 모든 세컨더리 인덱스가 PK 값을 포함하기 때문에 PK의 크기가 커지면 세컨더리 인덱스도 자동으로 크기가 커진다.
5개의 세컨더리 인덱스를 가지는 테이블의 경우
PK 크기가 커질수록 인덱스가 성능을 내기위해 필요한 메모리가 증가한다.
| PK 크기 | 레코드당 증가하는 인덱스 크기 | 100만 건 레코드 저장 시 증가하는 인덱스 크기 |
| 10B | 10B * 5 = 50B | 50B * 1,000,000 = 47MB |
| 50B | 50B * 5 = 250B | 250B * 1,000,000 = 238MB |
PK 는 메모리를 고려해 Auto-Increment 보다는 업무적인 컬럼으로 생성하는 것을 권장한다.
(3) 유니크 인덱스
유니크 인덱스는 세컨더리 인덱스와 구조상 차이가 없고 읽기 성능도 차이가 미미하다.
하지만 쓰기 작업에서는 유니크 인덱스가 중복된 값이 있는지 체크하는 과정이 필요하고 이로 인해 체인지 버퍼를 사용할 수 없어 세컨더리 인덱스보다 더 느리게 작동한다.
참고
'Database > MySQL' 카테고리의 다른 글
| [MySQL] 통계 정보 (0) | 2023.06.02 |
|---|---|
| [MySQL] MySQL의 격리 수준 (0) | 2023.06.02 |
| [MySQL] 옵티마이저의 데이터 처리 (0) | 2023.06.02 |
| [MySQL] B-Tree 인덱스를 통한 데이터 읽기 (0) | 2023.05.22 |
- Total
- Today
- Yesterday
- Stream
- JPA
- kafka
- H2
- MySQL
- spring rest docs
- HTTP 헤더
- 폴링 발행기 패턴
- 학습 테스트
- http
- 계층형 아키텍처
- mockito
- 클린코드
- named query
- Spring Boot
- Spring Data JPA
- 이벤트 스토밍
- java8
- 스프링 예외 추상화
- Spring
- Git
- 마이크로서비스 패턴
- 육각형 아키텍처
- 스프링 카프카 컨슈머
- Ubiquitous Language
- 도메인 모델링
- clean code
- TDD
- ATDD
- 트랜잭셔널 아웃박스 패턴
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |