
티스토리 뷰
목차
1. 스키마
2. 스키마 레지스트리
3. Avro
4. 스키마 레지스트리 동작 방식
5. 스키마 호환성
6. 스키마 레지스트리 실습
카프카를 사용하면서 스키마 레지스트리를 사용해야 하는 이유와 스키마 레지스트리의 동작 방식을 알아본다.
1. 스키마
카프카의 데이터 흐름은 대부분 브로트캐스트 방식이기 때문에 프로듀서를 일방적으로 신뢰할 수밖에 없는 방식이다. 따라서 프로듀서 관리자는 카프카 토픽의 데이터를 컨슘하는 관리자에게 반드시 데이터 구조를 설명해야 한다. 데이터를 컨슘하는 부서가 많고 관리자가 자주 바뀐다면 그때마다 데이터 구조를 설명하는 일이 쉬운 일은 아닐것이다. 이와 같이 데이터를 컨슘하는 여러 부서에게 그 데이터에 대한 정확한 정의와 의미를 알려주는 역할을 스키마를 통해 할 수 있다.
그 외에도 비즈니스 변화 등에 따라 모델링이나 데이터 포맷이 변경되는 경우 새로운 필드를 추가하거나 필드 이름을 변경 또는 삭제해야 하는데 이러한 스키마의 진화도 카프카에서 지원하기 때문에 애플리케이션들이 별다른 영향없이 스키마를 변경할 수 있다.
2. 스키마 레지스트리
스키마 레지스트리는 카프카에서 스키마를 등록하고 관리하는 별도의 애플리케이션이다.
프로듀서와 컨슈머는 스키마 레지스트리와 직접적으로 통신하는데 스키마 레지스트리가 지원하는 데이터 포맷을 사용해야 하며 대표적인 포맷이 Avro 이다.
3. Avro
Avro 는 시스템, 프로그래밍 언어, 프로세싱 프레임워크 사이에서 데이터 교환을 도와주는 오픈소스 직렬화 시스템이다.
스키마 레지스트리는 Avro, JSON, Protocol Buffer 포맷을 지원한다.
따라서 이 중 한 가지를 선택해 사용해야 하며 컨플루언트는 다음과 같은 이유로 Avro 포맷 사용을 권장한다.
- Avro는 JSON과 매핑된다.
- Avro는 매우 간결한 데이터 포맷이다.
- JSON은 메시지마다 필드 네임들이 포함되어 전송되므로 효율이 떨어진다.
- Avro는 바이너리 형태이므로 매우 빠르다.
{
"namespace": "student.avro",
"type": "record",
"doc": "This is an example of Avro.",
"name": "Student",
"fields": [
{"name": "name", "type": "string", "doc": "Name of the student"},
{"name": "class", "type": "int", "doc": "Class of the student"},
]
}- namespace: 이름을 식별하는 문자열
- type: Avro는 record, enums, arrays, maps 등을 지원
- doc: 사용자들에게 이 스키마 정의에 대한 설명 제공(주석)
- name: 레코드의 이름을 나타내는 문자열, 필수값
- fields: JSON 배열로서 필드들의 리스트를 뜻함
- name: 필드의 이름
- type: boolean, int, long, string 등의 데이터 타입 정의
- doc: 사용자들에게 해당 필드의 의미 설명(주석)
4. 스키마 레지스트리 동작 방식
프로듀서와 컨슈머가 각자 스키마 레지스트리와 통신하면서 스키마의 정보를 주고받을 수 있다.
프로듀서가 스키마 정보를 스키마 레지스트리에 등록함으로써 프로듀서가 전송하는 메시지의 크기와 컨슈머가 읽는 메시지의 크기도 줄일 수 있고 사전에 정의되지 않은 형식의 메시지는 전송할 수 없기 때문에 컨슈머에서 해당 처리에 대한 고민을 줄일 수 있다.

- 로컬 캐시에 없으면, 스키마 전송(등록)
Avro 프로듀서는 컨플루언트에서 제공하는 io.confluent.kafka.serializers.KafkaAvroSerializer 라는 새로운 직렬화를 사용해 스키마 레지스트리의 스키마가 유효한지 여부를 확인한다. 만약 스키마가 확인되지 않으면 Avro 프로듀서는 스키마를 등록하고 캐시한다. - 스키마 등록(ID 할당)
스키마 레지스트리는 현 스키마가 저장소에 저장된 스키마와 동일한 것인지, 진화한 스키마인지 확인한다. 스키마 레지스트리 자체적으로 각 스키마에 대해 고유 ID를 할당한다. 이 ID는 순차적으로 1씩 증가하지만, 반드시 연속적이진 않다. 스키마에 문제가 없다면 스키마 레지스트리라는 프로듀서에게 고유 ID를 응답한다. - 스키마 ID별 Avro 메시지 직렬화 전송
프로듀서는 스키마 레지스트리로부터 받은 스키마 ID를 참고해 메시지를 카프카로 전송한다. 이때 프로듀서는 스키마의 전체 내용이 아닌 오로지 메시지와 스키마 ID만 보낸다. JSON은 key:value 형태로 전체 메시지를 전송해야 하지만, Avro를 사용하면 프로듀서가 스키마 ID와 밸류만 메시지로 보내게 되어 카프카로 전송하는 전체 메시지의 크기를 줄일 수 있다. - 로컬 캐시에 없으면 스키마 ID별로 가져오기
Avro 컨슈머는 스키마 ID로 컨플루언트에서 제공하는 io.confluent.kafka.serializers.KafkaAvroDeserializer 라는 새로운 역직렬화를 사용해 카프카의 토픽에 저장된 메시지를 읽는다. 이때 컨슈머가 스키마 ID를 갖고있지 않다면 스키마 레지스트리로부터 가져온다.
5. 스키마 호환성
스키마 레지스트리는 하나의 서브젝트에 대한 버전 정보별로 진화하는 각 스키마를 고유한 ID와 함께 관리해준다. 또한 스키마가 진화함에 따라 호환성 레벨을 검사해야 하는데, 스키마 레지스트리에서는 BACKWARD, FORWARD, FULL 호환성 레벨을 제공한다.
1) BACKWARD 호환성
BACKWARD 호환성은 진화된 스키마를 적용한 컨슈머가 진화 전의 스키마가 적용된 프로듀서가 보낸 메시지를 읽을 수 있도록 허용하는 호환성이다.

| 호환성 레벨 | 지원 버전(컨슈머 기준) | 변경 허용 항목 | 스키마 업데이트 순서 |
| BACKWARD | 자신과 동일한 버전과 하나 아래의 하위 버전 | 필드 삭제, 기본 값이 지정된 필드 추가 |
컨슈머 -> 프로듀서 |
| BACKWARD_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 하위 버전 |
2) FORWARD 호환성
FORWARD 호환성은 진화된 스키마가 적용된 프로듀서가 보낸 메시지를 진화 전의 스키마가 적용된 컨슈머가 읽을 수 있게 하는 호환성이다.
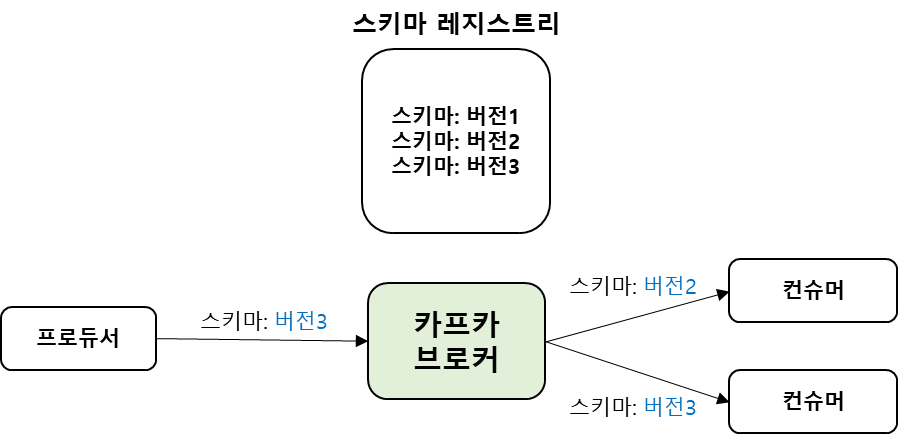
| 호환성 레벨 | 지원 버전(컨슈머 기준) | 변경 허용 항목 | 스키마 업데이트 순서 |
| FORWARD | 자신과 동일한 버전과 하나 위의 상위 버전 |
필드 추가, 기본 값이 지정된 필드 삭제 |
프로듀서 -> 컨슈머 |
| FORWARD_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 상위 버전 |
3) FULL 호환성
FULL 호환성은 BACKWARD와 FORWARD 호환성 모두를 지원한다.
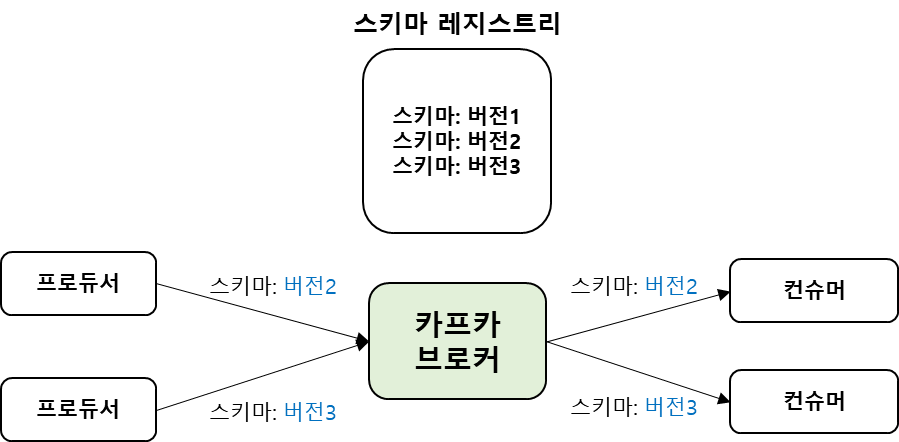
| 호환성 레벨 | 지원 버전(컨슈머 기준) | 변경 허용 항목 | 스키마 업데이트 순서 |
| FULL | 자신과 동일한 버전과 하나 위 또는 하나 아래 버전 |
기본값이 지정된 필드 추가, 기본 값이 지정된 필드 삭제 | 순서 상관 없음 |
| FULL_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 상위 버전과 하위 버전 |
6. 스키마 레지스트리 실습
프로젝트 구성
- Java 11
- Spring boot 2.7.9
- Oracle VM VirtualBox
- Confluent Kafka 7.2.1
VM에 Confluent Kafka 를 구성하고 주키퍼, 카프카, 스키마 레지스트리 순서로 기동한다.
IP: 192.168.56.101
zookeeper-server-start etc/kafka/zookeeper.properties
kafka-server-start etc/kafka/server.properties
schema-registry-start etc/schema-registry/schema-registry.properties
Confluent Cloud Schema Registry and Spring Boot 를 참고해 Spring boot 프로젝트를 설정한다.
build.gradle
plugins {
id "com.github.davidmc24.gradle.plugin.avro" version "1.2.0"
id "idea"
}
repositories {
gradlePluginPortal()
mavenCentral()
maven {
url "https://packages.confluent.io/maven"
}
}
dependencies {
implementation 'org.springframework.kafka:spring-kafka'
implementation 'org.apache.avro:avro:1.11.0'
implementation "io.confluent:kafka-avro-serializer:6.1.0"
}
application.properties
spring.kafka.producer.bootstrap-servers=192.168.56.101:9092
spring.kafka.producer.properties.schema.registry.url=http://192.168.56.101:8081
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=io.confluent.kafka.serializers.KafkaAvroSerializer
src/main/avro/ReviewMessage.avsc
{
"type": "record",
"name": "ReviewMessage",
"namespace": "com.papaco.avro.schema",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "mateId",
"type": "string"
},
{
"name": "status",
"type": "string"
}
]
}
Gradle 탭에서 Tasks > source generation > generateAvro 를 실행하면 build/generated-main-avro-java 패키지에 ReviewMessage.avsc 파일을 사용해 ReviewMessage Java 클래스가 생성된다.
kafkaTemplate 을 이용해 브로커로 메시지를 전송한다.
KafkaTemplate<String, ReviewMessage> kafkaTemplate;
Schema Registry API 를 통해 스키마 정보를 확인할 수 있다.
$ curl -s "http://localhost:8081/subjects/papaco.review-value/versions/1"
{"subject":"papaco.review-value","version":1,"id":1,"schema":"{\"type\":\"record\",\"name\":\"ReviewMessage\",\"namespace\":\"com.papaco.avro.schema\",\"fields\":[{\"name\":\"id\",\"type\":{\"type\":\"string\",\"avro.java.string\":\"String\"}},{\"name\":\"mateId\",\"type\":{\"type\":\"string\",\"avro.java.string\":\"String\"}},{\"name\":\"status\",\"type\":{\"type\":\"string\",\"avro.java.string\":\"String\"}}]}"}
kafka-avro-console-consumer 를 통해 전송된 데이터를 카프카 서버에서 확인할 수 있다.
$ kafka-avro-console-consumer \
--topic papaco.review \
--property schema.registry.url=http://localhost:8081 \
--bootstrap-server localhost:9092 \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property print.key=true \
--property key.separator="-" \
--from-beginning
e747975b-caa3-402a-bf10-a4aca10473f6-{"id":"e747975b-caa3-402a-bf10-a4aca10473f6","mateId":"6fec2b25-9ad4-4dba-9f54-bc3c3305a6a5","status":"DEMANDED"}
참고
'Kafka' 카테고리의 다른 글
| [Kafka] Spring Kafka 구성(Broker, Producer, Consumer) (0) | 2023.03.21 |
|---|---|
| [Kafka] 4. 카프카 컨슈머 (0) | 2023.02.02 |
| [Kafka] 3. 카프카 프로듀서 (0) | 2023.02.02 |
| [Kafka] 2. 토픽과 파티션 (0) | 2023.02.02 |
| [Kafka] 1. 카프카 기본 개념 (0) | 2023.02.01 |
- Total
- Today
- Yesterday
- Spring Boot
- TDD
- ATDD
- 계층형 아키텍처
- Ubiquitous Language
- 육각형 아키텍처
- kafka
- mockito
- Spring Data JPA
- 학습 테스트
- java8
- 도메인 모델링
- JPA
- 클린코드
- spring rest docs
- HTTP 헤더
- Git
- Stream
- 이벤트 스토밍
- 스프링 카프카 컨슈머
- named query
- clean code
- H2
- MySQL
- Spring
- http
- 폴링 발행기 패턴
- 마이크로서비스 패턴
- 스프링 예외 추상화
- 트랜잭셔널 아웃박스 패턴
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |