
티스토리 뷰
목차
1. 적정 파티션 개수
2. 토픽 정리 정책
3. 멀티 노드 카프카 클러스터
4. 복제와 리더 / 팔로워 파티션
5. ISR
6. Kafka Config
토픽과 파티션을 사용함에 있어 발생하는 여러가지 운영상 고려사항을 확인하고 멀티 노드 카프카 클러스터를 구성한다.
1. 적정 파티션 개수
토픽의 파티션 개수는 카프카의 성능과 관련이 있기 때문에 적절한 파티션 개수를 설정하고 운영하는 것이 매우 중요하다.
토픽 생성시 파티션 개수 고려사항
- 데이터 처리량
- 메시지 키 사용 여부
- 브로커, 컨슈머 영향도
1) 데이터 처리량
데이터 처리량을 늘리기 위해 파티션을 추가하고 파티션 개수만큼 컨슈머를 추가해서 병렬 처리량을 늘릴 수 있다.
(컨슈머가 실행되는 서버의 사양을 올리는 스케일업이나 GC 튜닝 등 컨슈머의 처리량을 늘리는 방법도 있다.)
프로듀서가 보내는 데이터 양과 컨슈머의 데이터 처리량을 계산해서 파티션 개수를 정할 수 있다.
프로듀서 전송 데이터량 < 컨슈머 데이터 처리량 x 파티션 개수
- 프로듀서가 보내는 데이터가 초당 1,000 레코드이고,
- 컨슈머가 처리할 수 있는 데이터가 초당 100 레코드이면,
- 파티션 개수는 10
2) 컨슈머 데이터 처리량
파티션 개수만큼 컨슈머 스레드를 운영한다면 병렬처리를 극대화할 수 있다.
전체 컨슈머 데이터 처리량이 프로듀서가 보내는 데이터보다 적다면 컨슈머 랙이 생기기 때문에 컨슈머 전체 데이터 처리량은 프로듀서 데이터 처리량보다 많아야 한다.
컨슈머 데이터 처리량 측정
- 컨슈머 데이터 처리량은 운영중인 카프카에서 더미 데이터 테스트로 구할 수 있다.
- 그리고 프로듀서가 보내는 데이터 양을 하루, 시간, 분 단위로 쪼개서 예측한다.
- 데이터의 최대치를 데이터 생성량으로 잡는다.
3) 메시지 키 사용 여부
메시지 키를 사용하면 데이터 처리 순서가 보장받지 못하는 경우가 생길 수 있다.
[ 파티션 추가 전 ]

[ 파티션 추가 후 ]

프로듀서가 기본 파티셔너를 사용할 때,
- 메시지 키를 사용하면 프로듀서가 토픽으로 데이터를 보낼 때 메시지 키를 해시 변환하여 메시지 키를 파티션에 매칭시킨다.
- 만약 파티션 개수가 달라지면 이미 매칭된 파티션과 메시지 키의 매칭이 깨지고 전혀 다른 파티션에 데이터가 할당된다.
- 파티션을 변환하기 이전과 이후 메시지 키의 파티션 위치가 달라지기 때문에 컨슈머는 메시지 키의 순서를 더는 보장받지 못한다.
따라서 메시지 처리 순서가 보장되어야 한다면,
파티션 개수를 프로듀서가 전송하는 데이터양보다 더 넉넉하게 잡고 최대한 파티션의 변화가 발생하지 않는 방향으로 운영해야 한다.
만약에 파티션 개수가 변해야 하는 경우에는 기존에 사용하던 메시지 키의 매칭을 그대로 가져가기 위해 커스텀 파티션너를 개발하고 적용해야 한다.
4) 브로커와 컨슈머의 영향도
파티션은 각 브로커의 파일 시스템을 사용하기 때문에 파티션이 늘어나는 만큼 브로커에서 접근하는 파일 개수가 많아진다. 그런데 운영체제에서는 프로세스당 열 수 있는 파일 최대 개수를 제한하고 있다. 만약 브로커가 관리하는 파티션 개수가 너무 많다면 파티션 개수를 분산하기 위해서 카프카 브로커 개수를 늘리는 방안도 고려해야 한다.
2. 토픽 정리 정책
토픽의 데이터를 더는 사용하지 않는 경우 cleanup.policy 옵션을 사용해 데이터를 완전 삭제(delete)하거나 압축(compact)으로 동일 메시지 키의 가장 오래된 데이터를 삭제할 수 있다.
1) 토픽 삭제 정책(delete policy)
cleanup.policy 옵션을 delete로 설정하면 토픽의 데이터를 삭제 한다.
토픽의 데이터는 세그먼트 단위로 삭제된다.
세그먼트
세그먼트는 토픽의 데이터를 저장하는 명시적인 파일 시스템 단위이고, 파티션마다 별개로 생성되며 파일 이름은 오프셋 중 가장 작은 값이 된다.
segment.bytes 옵션으로 1개의 세그먼트 크기를 설정할 수 있다. segment.bytes 크기보다 커질 경우에는 기존에 적재하던 세그먼트 파일을 닫고 새로운 세그먼트를 열어서 데이터를 저장한다.
삭제 주기
retention.ms는 토픽의 데이터를 유지하는 기간을 밀리초 단위로 설정할 수 있다.
세그먼트 파일의 마지막 수정 시간이 retention.ms를 넘어가면 세그먼트는 삭제된다.
retention.bytes는 토픽의 최대 데이터 크기를 제어한다.
retention.bytes를 넘어간 세그먼트 파일들은 삭제된다.
2) 토픽 압축 정책(compact policy)

cleanup.policy 옵션을 compact로 설정하면 메시지 키별로 해당 메시지 키의 레코드 중 오래된 데이터를 삭제한다.
동일한 메시지 키를 기준으로 오래된 데이터를 삭제하기 때문에 파티션의 오프셋과 관계없이 중간에 있는 레코드가 삭제될 수 있다.
* 액티브 세그먼트: 데이터를 저장하기 위해 사용중이 세그먼트
압축 정책은 액티브 세그먼트를 제외한 나머지 세그먼트들에 한해서만 데이터를 처리한다.
* 테일(tail) 영역: 압축 정책에 의해 압축이 완료된 레코드들
테일 영역의 레코드들을 클린 레코드라고 한다.
* 헤드(head) 영역: 압축이 진행되지 않은 레코드들
헤드 영역의 레코드들을 더티 레코드라고 한다.
더티 비율
더티 비율은 더티 영역의 메시지 개수를 압축 대상 세그먼트에 남아있는 데이터의 총 레코드 수로 나눈 비율을 뜻한다.
더티비율
= 더티 레코드 개수 / 총 레코드 수(클린 레코드 개수 + 더티 레코드 개수)
= 3 / (3 + 3)
= 0.5
압축 시작 시점
min.cleanable.dirty.ratio 옵션값으로 데이터의 압축 시작 시점을 결정한다.
min.cleanable.dirty.ratio 옵션값은 액티브 세그먼트를 제외한 세그먼트에 남아있는 데이터의 테일 영역의 레코드 개수와 헤드 영역의 레코드 개수의 비율을 뜻한다.
min.cleanable.dirty.ratio를 0.5로 설정할 경우 더티 비율이 0.5가 넘어가면 압축이 수행된다.
- 0.9와 같이 크게 설정하면 한번 압축을 할 때 많은 데이터가 줄어들므로 압축 효과가 좋지만 압축 전까지 많은 용량을 차지하게된다.
- 0.1과 같이 작게 설정하면 압축이 자주 일어나기 때문에 최신 데이터만 유지할 수 있지만 압축이 자주 발생하므로 브로커에 부담을 주게된다.
3. 멀티 노드 카프카 클러스터
카프카는 데이터 복제(Replication)을 통해 분산 시스템 기반에서 카프카의 최적 가용성을 보장한다.
EC2 인스턴스를 활용해 멀티 노드 카프카 클러스터를 구성한다.
1) 설치 및 기본 설정
(1) EC2 인스턴스 생성 및 접속
zookeeper 1, broker 3대를 설치할 총 4개의 인스턴스를 생성한다.

zookeeper의 보안그룹을 설정한다.

kafka 브로커의 보안그룹을 설정한다.

EC2에 접속한다.

(2) host 설정
[ec2 인스턴스]
$ sudo vi /etc/hosts
13.125.172.62 zookeeper
13.124.8.60 kafka-0
43.201.102.129 kafka-1
43.201.149.82 kafka-2
(3) 별칭 설정
[ec2 인스턴스]
$ vi ~/.bashrc
USERNAME=zookeeper
PS1='[\e[1;31m$USERNAME\e[0m][\e[1;32m\t\e[0m][\e[1;33m\u\e[0m@\e[1;36m\h\e[0m \w] \n\$ \[\033[00m\]'
$ source ~/.bashrc
(4) Java 설치
[ec2 인스턴스]
$ cd ~
# aws coreetto 다운로드
$ sudo curl -L https://corretto.aws/downloads/latest/amazon-corretto-11-x64-linux-jdk.rpm -o jdk11.rpm
# jdk11 설치
$ sudo yum localinstall jdk11.rpm
# jdk version 선택
$ sudo /usr/sbin/alternatives --config java
# java 버전 확인
$ java --version
# 다운받은 설치키트 제거
$ rm -rf jdk11.rpm
(5) 카프카 설치
[ec2 인스턴스]
$ wget https://downloads.apache.org/kafka/3.4.0/kafka_2.12-3.4.0.tgz
$ tar xvf kafka_2.12-3.4.0.tgz
$ cd kafka_2.12-3.4.0.tgz
(6) 카프카 브로커 힙 메모리 설정
[ec2 인스턴스]
$ vi ~/.bashrc
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m"
$ source ~/.bashrc
$ echo $KAFKA_HEAP_OPTS
3) 멀티 브로커 구성
1개의 zookeeper에 연결된 3개의 멀티 브로커를 구성한다.
(1) 주키퍼 실행 옵션 설정
[zookeeper]
$ vi config/zookeeper.properties
dataDir=/home/ec2-user/data/zookeeper-logs
$ mkdir -p /home/ec2-user/data/zookeeper-logs
(2) 카프카 브로커 실행 옵션 설정
[kafka-x]
$ vi config/server.properties
broker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://kafka-x-IP:9092
log.dirs=/home/ec2-user/data/kafka-logs
zookeeper.connect=zookeeper:2181
$ mkdir -p /home/ec2-user/data/kafka-logs
(3) 주키퍼 실행
[zookeeper]
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
$ jps -vm
(4) 브로커 실행
[kafka-x]
$ bin/kafka-server-start.sh -daemon config/server.properties
$ jps -m
(5) 브로커 로그 확인
[kafka-x]
$ tail -f logs/server.log
파일 시스템 구조
home
├── ec2-user
│ ├── data
│ │ ├── zookeeper-logs
│ │ ├── kafka-logs
│ ├── kafka_2.12-3.4.0
│ │ ├── bin
│ │ │ ├── kafka-configs.sh
│ │ │ ├── kafka-console-consumer.sh
│ │ │ ├── kafka-console-producer.sh
│ │ │ ├── kafka-server-start.sh
│ │ │ ├── kafka-topics.sh
│ │ │ ├── zookeeper-server-start.sh
│ │ ├── config
│ │ │ ├── server.properties
│ │ │ └── zookeeper.properties
│ │ ├── libs
│ │ ├── LICENSE
│ │ ├── logs
│ │ │ ├── server.log
│ │ ├── NOTICE
│ │ └── site-docs
4. 복제와 리더 / 팔로워 파티션
데이터 복제는 카프카를 장애 허용 시스템으로 동작하도록 하는 원동력이다. 데이터 복제로 클러스터로 묶인 브로커 중 일부에 장애가 발생하더라도 데이터를 유실하지 않고 안전하게 사용할 수 있다.
데이터 복제는 파티션 단위로 이루어지고 토픽을 생성할 때 파티션의 복제 개수(replication factor)를 설정할 수 있다.
직접 선택하지 않으면 브로커에 설정된 옵션 값을 따라간다.(기본값 1)
토픽 생성
파티션 3, replication factor 3
[kafka-0]
$ bin/kafka-topics.sh --create \
--bootstrap-server kafka-0:9092,kafka-1:9092,kafka-2:9092 \
--replication-factor 3 \
--partitions 3 \
--topic topic-p3r3
토픽 정보 확인
[kafka-0]
$ bin/kafka-topics.sh --describe \
--bootstrap-server kafka-0:9092,kafka-1:9092,kafka-2:9092 \
--topic topic-p3r3
Topic: topic-p3r3 TopicId: pdUUUMzuSd2-xuD2kgrmFg PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: topic-p3r3 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: topic-p3r3 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: topic-p3r3 Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0파티션을 기준으로 Leader 브로커, Replica 브로커, Isr(리더,브로커)을 확인할 수 있다.

메시지 전송
[kafka-0]
$ bin/kafka-console-producer.sh --bootstrap-server kafka-0:9092,kafka-1:9092,kafka-2:9092 --topic topic-p3r3
>hello kafka
프로듀서가 전송할 파티션을 결정하면 해당 파티션의 리더에게 메시지를 전송한다.
팔로워 파티션들은 리더 파티션의 데이터를 가져와 복제한다.

메시지 확인
[kafka-0]
$ bin/kafka-dump-log.sh --deep-iteration --print-data-log --files /home/ec2-user/data/kafka-logs/topic-p3r3-0/00000000000000000000.log
Dumping /home/ec2-user/data/kafka-logs/topic-p3r3-0/00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: 0 lastSequence: 0 producerId: 0 producerEpoch: 0 partitionLeaderEpoch: 3 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1676881897607 size: 79 magic: 2 compresscodec: none crc: 1301629467 isvalid: true
| offset: 0 CreateTime: 1676881897607 keySize: -1 valueSize: 11 sequence: 0 headerKeys: [] payload: hello kafka
5) 컨트롤러 브로커
컨트롤러 브로커는 브로커들의 파티션 리더를 선출하는 역할을 하는데, 컨트롤러는 주키퍼에 의해 결정된다.
주키퍼
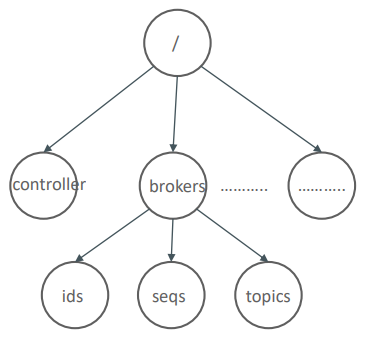
주키퍼는 디렉토리 구조 기반의 Z Node를 활용해 개별 노드의 중요 정보를 담고 있으며 Z Node를 계속 모니터링하며 Z Node에 변경 발생 시 Watch Event가 트리거 되어 변경 정보가 개별 노드들에 통보한다.
[zookeeper]
$ bin/zookeeper-shell.sh localhost:2181
# 노드 확인
ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
# 컨트롤러 확인
get /controller
{"version":2,"brokerid":0,"timestamp":"1676881398744","kraftControllerEpoch":-1}
클러스터에서 주키퍼의 역할은 다음과 같다
- Controller Broker 선출(Election)
- Kafka 클러스터내 Broker들의 List, Broker Join/Leave 관리 및 통보
- Topic의 파티션, replicas등의 정보를 가짐
Heartbeat
카프카 브로커는 주기적으로 Zookeeper에 접속하면서 Session Heartbeat을 전송하여 자신의 상태를 보고하는데
Zookeeeper는 zookeeper.session.timeout.ms 이내에 Heartbeat을 받지 못하면 해당 브로커의 노드 정보를 삭제하고 Controller 노드에게 변경 사실을 통보한다.
컨트롤러
Zookeeper에 가장 처음 접속을 요청한 Broker가 Controller가 되고 Controller는 파티션에 대한 Leader Election을 수행한다.
Leader Election
Controller는 Zookeeper로 부터 broker 추가/Down등의 정보를 받으면 해당 broker로 인해 영향을 받는 파티션들에 대해서 새로운 Leader Election을 수행한다.

- broker-2 Shutdown
- Zookeeper는 session 기간동안 Heartbeat이 오지 않으므로 broker-2의 노드 정보 갱신
- Controller는 Zookeeper를 모니터링 하던 중 Watch Event로 broker-2에 대한 Down 정보를 받음
- Controller는 다운된 브로커가 관리하던 파티션들에 대해 새로운 Leader/Follower 결정
- 결정된 새로운 Leader/Follower 정보를 Zookeeper에 저장
- 해당 파티션을 복제하는 모든 브로커들에게 새로운 Leader/Follower 정보를 전달하고 새로운 Leader로 부터 복제 수행할 것을 요청
- Controller는 모든 브로커가 가지는 Metadatacache를 새로운 Leader/Follower 정보로 갱신할 것을 요청


4. ISR

ISR(In-Sync-Replicas)은 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태를 뜻한다.
리더 파티션에 새로운 레코드가 추가되어 오프셋이 증가하면 팔로워 파티션이 위치한 브로커는 리더 파티션의 데이터를 복제하는데 리터 파티션에 데이터가 적제된 이후 팔로워 파티션이 복제하는 시간차 때문에 리터 파티션과 팔로워 파티션 간에 오프셋 차이가 발생한다.
리더 파티션은 replica.lag.time.max.ms 만큼의 주기를 가지고 팔로워 파티션이 데이터를 복제하는지 확인한다.
replica.lag.time.max.ms값보다 긴 시간동안 데이터를 가져가지 않는다면 해당 팔로워 파티션에 문제가 생긴 것으로 판단하고 ISR 그룹에서 제외한다.

min.insync.replicas 파라미터는 브로커의 설정값으로 Producer가 acks=all 로 성공적으로 메시지를 보낼 수 있는 최소한의 ISR 브로커 개수를 의미한다. 프로듀서의 Acks=all 일때, min.insync.replicas 값보다 ISR 브로커의 개수가 작으면 프로듀서에게 Error를 반환한다. (NotEnoughReplicasException 또는 NotEnoughReplicasAfterAppendException)
1) 리더 파티션 선출
(1) Preferred Leader Election
파티션 별로 최초 할당된 Leader/Follower Broker설정을 Preferred Broker로 그대로 유지한다.
auto.leader.rebalance.enable=true, leader.imbalance.check.interval.seconds를 일정시간으로 설정(기본 300초)하면 브로커가 shutdown후 재 기동될 때 Preferred Leader Broker를 일정 시간 이후에 리더로 재선출한다.

Topic: topic-p3r3 TopicId: pdUUUMzuSd2-xuD2kgrmFg PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: topic-p3r3 Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0
Topic: topic-p3r3 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0
Topic: topic-p3r3 Partition: 2 Leader: 0 Replicas: 2,1,0 Isr: 0
(2) Unclean Leader Election
unclean.leader.election.enable 옵션으로 ISR이 아닌 팔로워 파티션을 리더 파티션으로 선출 가능한지 여부를 선택할 수 있다.
unclean.leader.election.enable: false
- ISR이 아닌 팔로워 파티션을 리더로 선출하지 않는다.
- 리더 파티션이 존재하는 브로커가 다시 시작되기 까지 기다리기 때문에 서비스가 중단된다.
- 대신 데이터의 유실은 발생하지 않는다.

Topic: topic-p3r3 TopicId: pdUUUMzuSd2-xuD2kgrmFg PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: topic-p3r3 Partition: 0 Leader: none Replicas: 1,0,2 Isr: 0
Topic: topic-p3r3 Partition: 1 Leader: none Replicas: 0,2,1 Isr: 0
Topic: topic-p3r3 Partition: 2 Leader: none Replicas: 2,1,0 Isr: 0
unclean.leader.election.enable: true
- ISR이 아닌 팔로워 파티션이 리더로 선출될 수 있다.
- 서비스가 중단되지 않는다.
- 동기화되지 않은 파티션이 리더로 선출되므로 일부 데이터가 유실될 수 있다.
$ bin/kafka-configs.sh --bootstrap-server broker-1:9092 \
--entity-type topics \
--entity-name topic-p3r3 \
--describe --all | grep unclean
... unclean.leader.election.enable=false ...
$ bin/kafka-configs.sh --bootstrap-server broker-1:9092 \
--entity-type topics \
--entity-name topic-p3r3 \
--alter \
--add-config unclean.leader.election.enable=true
일부 데이터가 유실되더라도 토픽과 연동 중인 서비스의 무중단이 더 중요하다면 true,
서비스가 중단되더라도 데이터가 유실되면 안되는 경우 false로 설정한다.
6. Kafka Config
| Config 구분 | 설명 |
| Broker와 Topic 레벨 Config | • Kafka 서버에서 설정되는 Config • Topic의 Config 값은 Broker 레벨에서 지정한 Config를 기본으로 설정하며 별도의 Topic 레벨 Config를 설정할 경우 이를 따름 • 보통 server.properties에 있는 Config는 변경시 Broker 재기동이 필요한 Static Config이며, Dynamic Config는 kafka-configs를 이용하여 동적으로 config 변경 가능. |
| Producer와 Consumer 레벨 Config | • Kafka 클라이언트에서 설정되는 Config • Client 레벨에서 설정되므로 server.properties에 존재하지 않고, kafka-configs로 수정할 수 없으며 Client 수행시마다 설정할 수 있음 |
kafka-configs.sh 명령어로 브로커와 토픽 레벨의 설정을 변경할 수 있다.
# broker 0번의 config 설정 확인
$ bin/kafka-configs.sh --bootstrap-server kafka-0:9092 --entity-type brokers --entity-name 0 --all --describe
# topic의 config 설정 확인
$ bin/kafka-configs.sh --bootstrap-server kafka-0:9092 --entity-type topics --entity-name multipart-topic --all --describe
$ bin/kafka-configs.sh --bootstrap-server kafka-0:9092 --entity-type topics --entity-name multipart-topic --all --describe \
| grep max.message.bytes
# topic의 config 설정 변경
$ bin/kafka-configs.sh --bootstrap-server kafka-0:9092 --entity-type topics --entity-name multipart-topic --alter \
--add-config max.message.bytes=2088000
# 변경한 topic의 config를 다시 Default값으로 원복
$ bin/kafka-configs.sh --bootstrap-server kafka-0:9092 --entity-type topics --entity-name multipart-topic --alter \
--delete-config max.message.bytes
참고
'Kafka' 카테고리의 다른 글
| [Kafka] 5. 스키마 레지스트리 (0) | 2023.04.18 |
|---|---|
| [Kafka] Spring Kafka 구성(Broker, Producer, Consumer) (0) | 2023.03.21 |
| [Kafka] 4. 카프카 컨슈머 (0) | 2023.02.02 |
| [Kafka] 3. 카프카 프로듀서 (0) | 2023.02.02 |
| [Kafka] 1. 카프카 기본 개념 (0) | 2023.02.01 |
- Total
- Today
- Yesterday
- MySQL
- 폴링 발행기 패턴
- mockito
- Stream
- spring rest docs
- 계층형 아키텍처
- 마이크로서비스 패턴
- kafka
- 스프링 예외 추상화
- Ubiquitous Language
- JPA
- TDD
- java8
- Spring
- 스프링 카프카 컨슈머
- 도메인 모델링
- 클린코드
- clean code
- 이벤트 스토밍
- 학습 테스트
- Spring Boot
- ATDD
- 육각형 아키텍처
- Spring Data JPA
- H2
- HTTP 헤더
- http
- 트랜잭셔널 아웃박스 패턴
- named query
- Git
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |